Chaos Monkey Across Three Time Zones: A Field Report
Stress-testing Kubernetes across continents: what broke, what worked, and what we learned.


A story-driven post on stress-testing a global Kubernetes cluster with an open-sourced chaos suite
Chaos is a great teacher - especially when it’s 2 a.m. in Bangalore and your Frankfurt node just died.
Everyone loves a sleek Kubernetes diagram in the slide deck. Fewer want to talk about what happens when a node in Singapore quietly misbehaves, West Coast traffic spikes, and your failover logic throws a tantrum because someone forgot to tag a pod. Welcome to distributed systems in the real world - where things break in stupid, preventable, timezone-dependent ways.
This post is our uncensored field report on building and breaking a global K8s cluster using our open-sourced chaos test suite. It’s what we wish we had before we tried this the first time. (Spoiler: a lot of YAMLs cried in the making.)
Let’s dig in.
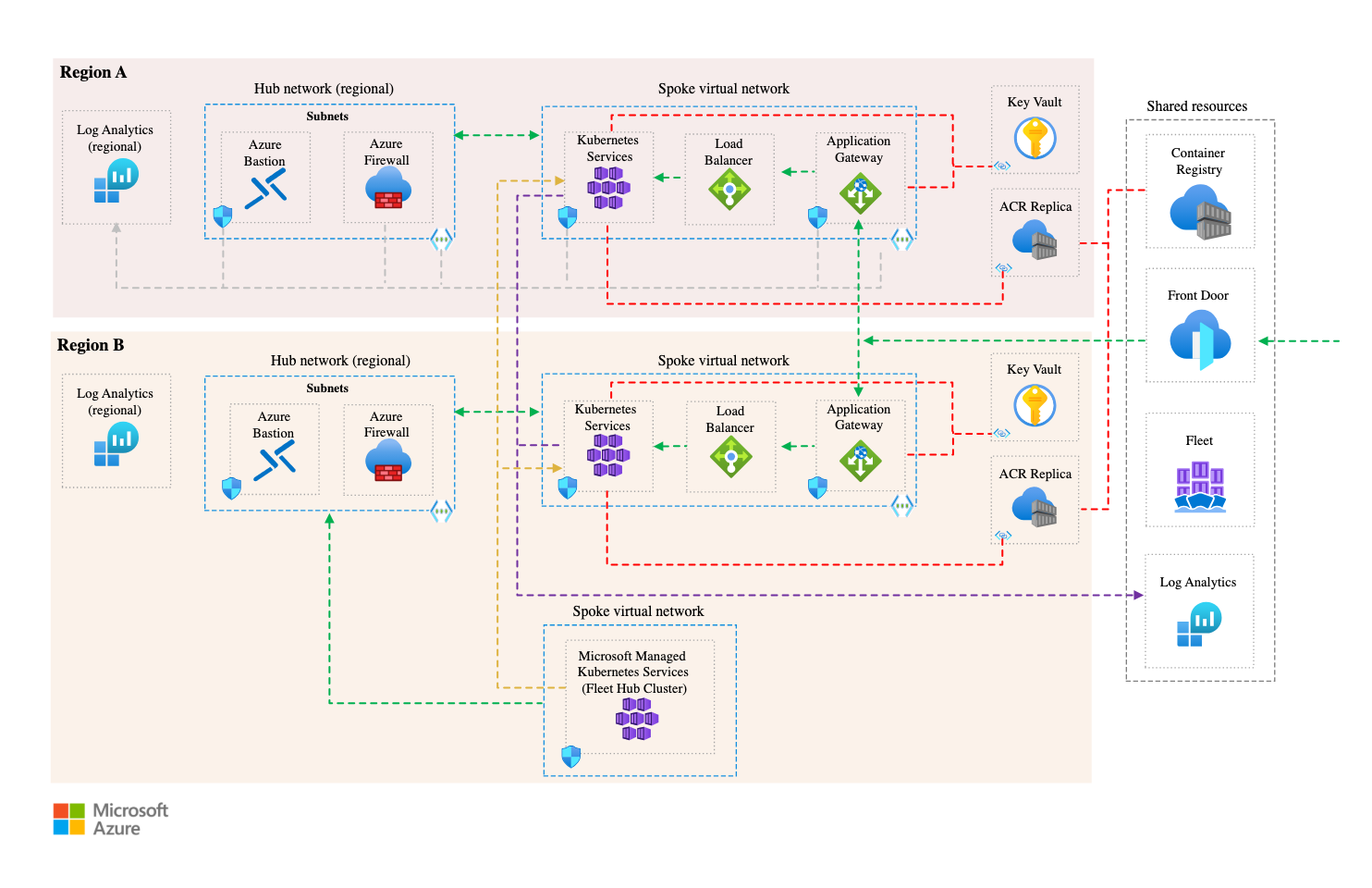
The Setup: A Masochist’s Playground
We built a three-region Kubernetes cluster - Virginia, Frankfurt, Singapore - connected via an Anycast CDN, with multi-zone failover policies. Because why test locally when you can melt things across the planet?
Here's what we were aiming for:
- Load balancing across the globe
- Resilient microservices with auto-restart, pod disruption budgets, and anti-affinity rules
- Zero-downtime deployments with progressive rollouts
- Observability baked in (Prometheus + Grafana + Loki + Jaeger cocktail)
We wanted to see: could this thing survive chaos, timezones, and a few poorly thought-out DevOps decisions?
Enter our chaos suite.
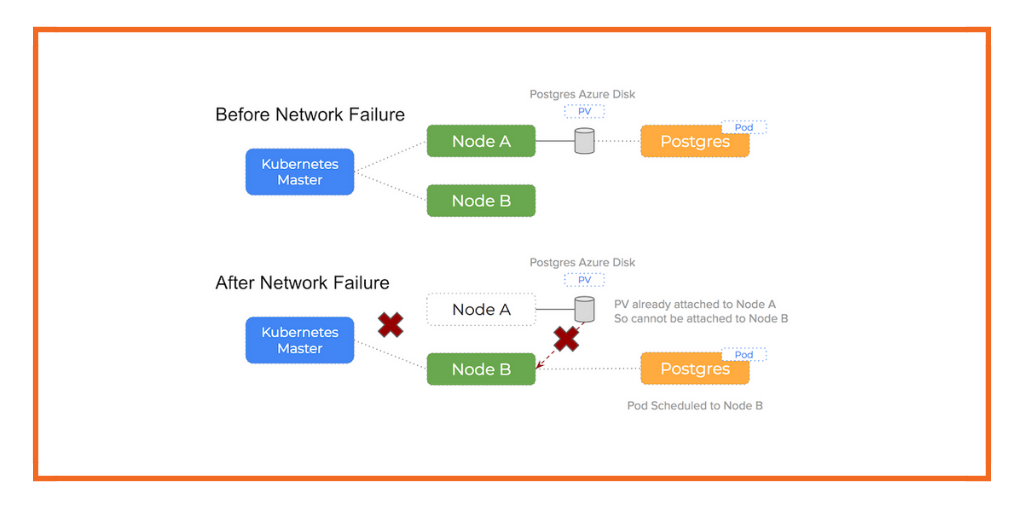
Nothing Breaks When You Want It To
We open-sourced a chaos toolkit that spins up fault injections like:
- Latency spikes in specific nodes (simulated with
tc qdisc) - Network partitions between regions
- Random pod evictions during active deployments
- Disk pressure and CPU starvation on key services
- Time skew - yes, clock drift - across nodes (this one broke more than we expected)
First test? Frankfurt goes dark during Singapore’s off-hours. The expected failover to Virginia worked. Kinda. But logs showed retries piling up because one container kept looking for a DNS entry that hadn’t propagated.
Lesson #1: Failover mechanics aren’t failover confidence. Just because Kubernetes says it restarted something doesn’t mean it works the way you want. Especially if your DNS TTLs are longer than your patience.
The Human Factor: Why “Follow-the-Sun” Is a Lie
Let’s talk ops. We had squads distributed across India, Central Europe, and US Pacific. Great for Git commits, awful for real-time incident triage. In one test, we saw elevated errors in Singapore at 3 a.m. local time. No alerts triggered - why? The alert rule was tuned for a US traffic pattern.
We also realized:
- Slack notifications went to sleeping engineers
- Alert fatigue is real when chaos tests overlap with actual issues
- Runbooks written by Day Shift You make no sense to Night Shift You
We’ve since built a dashboard that shows failure local time to give us cultural context. You’d be surprised how often incidents line up with off-hours deployments or sleepy human hands.

Code Smell: What We Got Wrong
Plenty.
We overestimated kube-probe’s ability to detect nuanced service degradation. Liveness probes passed even when our downstream dependencies were stuck in retry loops.
Our test suite missed scenarios like:
- Cloud provider API rate limits
- Unexpected node taints (someone ran a GPU experiment and forgot to clean up)
- OIDC token expiry in long-lived services
Also, we made the rookie mistake of assuming that chaos = outages. What we should’ve planned for was chaos = uncertainty. Which services get flakey? Which metrics lie? Who gets paged? That’s where the learning is.
Tools We Actually Use (and You Can Too)
We stitched together a chaos stack that’s yours for the stealing. Key tools:
- LitmusChaos for Kubernetes-native fault injections
- K6 for synthetic load testing during chaos runs
- OpenTelemetry for tracing across services
- Custom chaos-runner scripts in Go (we’ve open-sourced these here)
- GitHub Actions for scheduled chaos plans (“break things every Thursday 3pm UTC”)
We also added:
- A Slackbot that translates alerts into “who’s awake and actually on call”
- A Chaos Scoreboard: percentage of injected failures gracefully handled vs. recovered vs. totally borked
Want a TL;DR of our scoreboard?
Week 1: 27% survived cleanly
Week 3: 61%
Now: 78% and counting
Still not perfect. But at least we’re no longer scared of DNS TTLs. Mostly.
How Resilient Is Your Setup, Really?
Here’s a five-point sniff test we now use before declaring a system “resilient enough”:
- Time-zone aware runbooks? If your Frankfurt node dies at 2 a.m. Berlin time, does someone notice and know what to do?
- Can you kill any pod, anywhere, anytime - and stay alive?
- Observability tripwire coverage? Can you trace an error across at least 3 services and 2 regions?
- Service-level chaos tolerance? Not all services need 99.99%. Know which ones can fail without panic.
- Recovery experience, not just logic? Have your devs actually watched a cascading failure unfold?
If you score 4+ here, congrats. If not? Come join our next resilience workshop.

The Dumbest Bugs We Found
Quick laugh-cry list:
- A heartbeat service that didn’t log anything when it failed - because the logger was part of the failing module.
- A cronjob that triggered chaos tests at UTC+5:30 - but the cluster ran in UTC. Good morning, accidental Sunday meltdown.
- A misconfigured retry policy that re-sent a webhook 600 times in 6 minutes. Our payment partner was not amused.
We document these lovingly in our “Wall of WTFs.” It's a sacred hallway in our internal wiki. Some stories are now memes.
Break It Before You Fake It
Look, anyone can slap together a multi-region Kubernetes cluster with enough Terraform and coffee. But you don’t know your system until you watch it fall apart. On purpose.
Resilience isn’t a badge. It’s a muscle. And we’ve pulled a few, but we’re getting stronger.
We’re sharing our chaos suite because we think more teams should be doing this - with less pain. And if you want to dive deeper, our paid resilience workshop walks you through real-world setups, guided chaos runs, and blameless postmortems that don’t feel like HR rituals.
Want to build fault-tolerant infra without staying up all night? Join our next workshop - or just fork the chaos suite and tell us what breaks. We’re always listening.
FAQ
1. What is chaos engineering and why is it important for Kubernetes clusters?
Chaos engineering is the practice of intentionally injecting failures into systems to uncover hidden weaknesses and improve resilience. For Kubernetes clusters, especially global ones, this helps teams validate assumptions around fault tolerance, autoscaling, service discovery, and failover mechanisms before real incidents occur.
2. How does chaos testing differ in a multi-region Kubernetes setup?
In multi-region clusters, failures cascade across geographic, latency, and configuration boundaries. Chaos testing here isn’t just about pod evictions - it’s about simulating region-specific outages, time zone–induced alert blind spots, and inter-zone networking anomalies that single-region tests often miss.
3. What are some common failure modes revealed by global chaos experiments?
Real-world chaos tests frequently reveal DNS misconfigurations, misaligned probe thresholds, slow failovers due to outdated routing policies, misfired autoscaling events, and alerting gaps where rules were tuned for the wrong traffic patterns or time zones.
4. What tools are recommended for running chaos experiments in Kubernetes?
LitmusChaos is a popular Kubernetes-native chaos framework. K6 can simulate load under stress. OpenTelemetry provides observability glue. Combined with GitHub Actions or Argo Workflows, teams can schedule and automate chaos plans across environments.
5. How do you measure resilience during and after a chaos test?
A meaningful resilience score considers: time-to-detect, time-to-recover, user-facing error rate, and service degradation window. Teams often use SLO burn rates, error budgets, and “blast radius” impact metrics to quantify the blast and recovery zone.
6. Why is time zone awareness critical for distributed chaos engineering?
Incidents don’t care about your sleep cycle. Time zone mismatches lead to alert fatigue, misrouted on-call pages, and confusing postmortems. Including local timestamps and region tags in your dashboards and alert payloads dramatically improves triage.
7. What’s a good starting point for teams new to chaos testing?
Start small: test pod-level failures, simulate CPU stress or disk pressure on non-critical services, and gradually increase complexity. Always run chaos tests in staging first with observability enabled, and treat early tests as training runs - not fire drills.
8. Can chaos engineering help identify gaps in observability and alerting?
Yes - often it’s the first place you’ll feel the pain. Chaos events expose blind spots in tracing setups, silent failures missed by probes, and alert rules that look right in dashboards but never fire when things break in new ways.
9. How often should chaos tests be run in a production-like setup?
Ideally, chaos tests should be part of your regular CI/CD cadence - scheduled weekly or post-deploy using GitHub Actions, Jenkins, or similar. Consistency builds confidence. Some teams even run “GameDays” monthly to stress-test new features under failure.
10. What’s the biggest misconception about chaos engineering?
That it’s about breaking things randomly. Effective chaos engineering is hypothesis-driven, observability-backed, and safety-first. It’s not about reckless outages - it’s about learning how your system behaves under controlled disorder, so you’re not caught off guard when real chaos hits.


