From Monolith to Microservices: Planning Your Offshore Migration
Thinking microservices + offshore team = chaos? It doesn’t have to. This guide shows you how to pull it off without therapy.


How to slice the monolith without slicing your sleep schedule
Every CTO has had that fever dream. Your crusty, 400k-line monolith finally gets rewritten as clean, independently deployable microservices. Deploys happen daily. Engineers push code without crossing fingers. The offshore team hums along in parallel. Meanwhile, you sip cold brew on a Tuesday morning and smile.
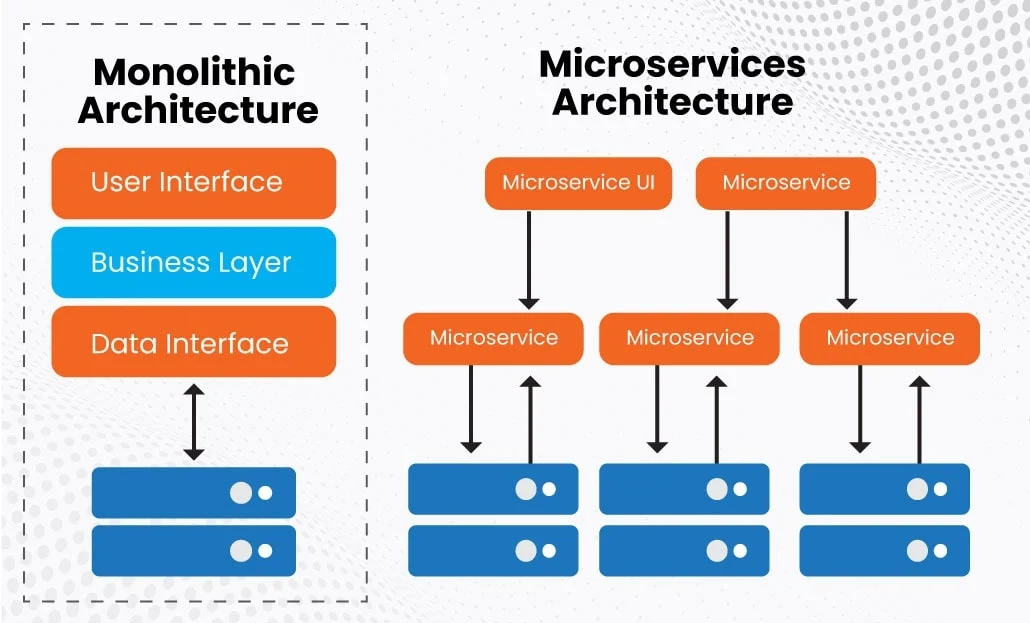
Reality? It’s mostly you at 3 a.m., firefighting in Slack while your distributed team tries to untangle a business-critical god-class in the middle of a sprint. Because - surprise - the “migration plan” was a PowerPoint with six arrows and zero database decisions.
This post is your roadmap to avoid that. No fluff, no "cloud-native digital agility" babble. Just hard-won lessons from moving real systems with real offshore teams.
Breaking Up Is Hard to Do
Let’s get this out of the way: decoupling a monolith isn’t a weekend project. It’s open-heart surgery while the patient runs a marathon. And when part of your team is 8,000 miles away, the stakes (and the time-zone juggling) get higher.
At 1985, we’ve helped teams split gnarly legacy apps - sometimes with zero docs, sometimes with an architect who quit in 2019. Every migration starts with the same gut check: Why are we doing this?
Not all monoliths are evil. Some are elegant, high-performing, and easier to maintain than a spaghetti-bowl of poorly coordinated services. So before you unleash the offshore rewrite brigade, make sure the pain is real:
- Are deploys brittle or blocked by unrelated code?
- Does a single change require navigating five unrelated modules?
- Is scaling bottlenecked by specific parts of the system?
- Do offshore devs struggle to onboard or contribute safely?
If you nodded more than twice, you’re probably ready. If not, maybe what you need is refactoring, not rewriting.
The Conway’s Law Trap
Here’s the kicker: Your microservices will mirror your team structure. That’s Conway’s Law, and it hits harder when your devs are split across time zones, companies, and cultures.
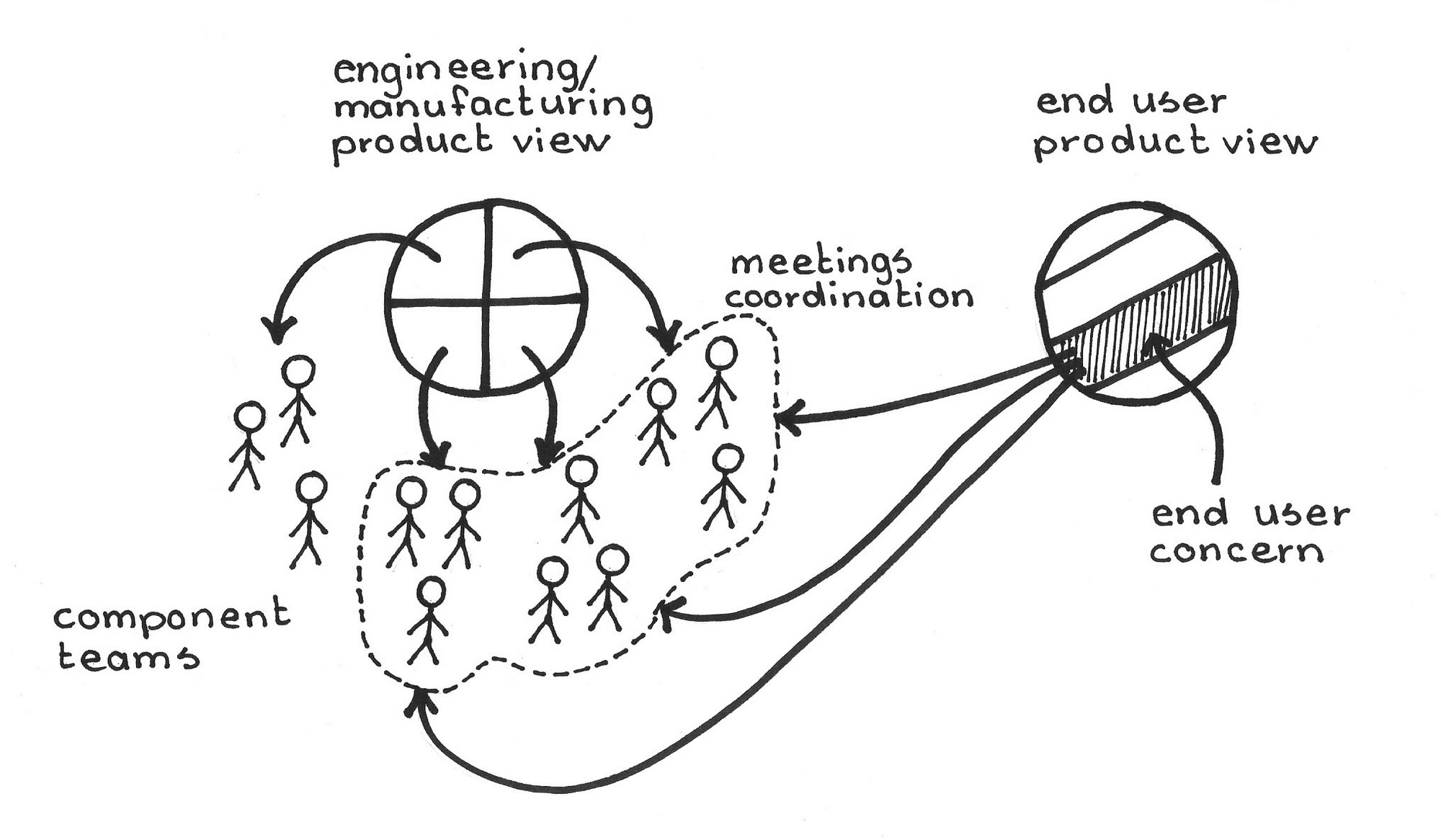
Offshore migrations fail when teams are siloed in weird, non-aligned ways. Like giving one squad the "User" service, another the "Auth" module, and a third the front-end app - but nobody owns the shared state model or deployment strategy.
What’s worked for us is domain-first service decomposition. That means defining services around clear business capabilities, not random tech chunks.
For example:
- “Orders” handles purchase flow, from cart to confirmation.
- “Payments” owns everything from gateway APIs to refund logic.
- “Accounts” covers signup, login, user preferences.
This is Domain-Driven Design (DDD) 101 - but when done right, it gives your offshore team autonomy. No more Slack convos at 1 a.m. just to deploy a schema change.
Bonus tip: appoint “domain stewards.” Each one owns the long-term integrity of their service, regardless of who’s coding today.
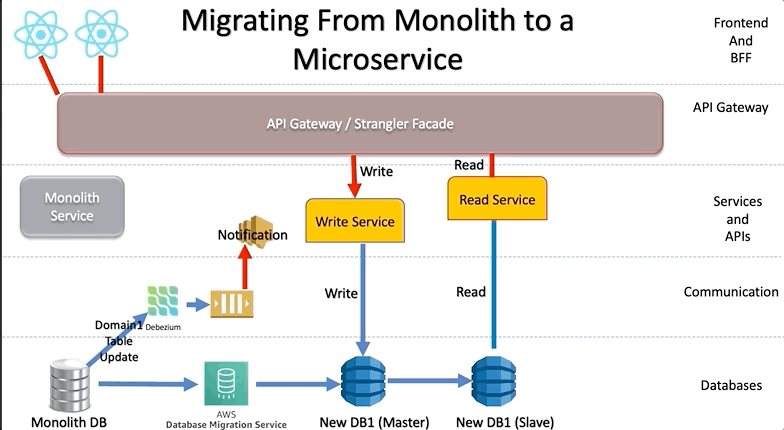
The Data Doesn’t Migrate Itself
Data is the dragon under the monolith. Most plans gloss over it. Then you end up with two services trying to update the same customer record, and things spiral faster than a Season 6 Succession argument.
We’ve tried it all - shared databases (bad), pub-sub replication (better), read replicas + CDC (even better), fully owned data per service (best, but hard).
Here’s our usual playbook:
- Service boundaries first. Define who owns what data.
- Strangle pattern. Route new writes to the microservice, let reads stay in the monolith until confidence builds.
- Dual-write cautiously. Only if you absolutely must - this is a ticking time bomb if your eventual consistency isn’t rock-solid.
- Automate audits. Build scripts to validate data sync between old and new worlds nightly.
And yes, write the damn migration plan down. In English. Not just in code diffs and tribal knowledge.
Hype vs. Ship
Somewhere between “Let’s go microservices!” and “Why does every service need its own CI pipeline, Dockerfile, Terraform module, observability stack, and lunch order bot?”, things go off the rails.
Here’s the anti-hype checklist we use to keep things grounded:
| Thing | Worth It? | Why |
|---|---|---|
| Separate repos for each service | ✅ | Easier CI/CD, clearer ownership |
| Shared platform team | ✅ | Avoid reinventing logging and metrics N times |
| Kubernetes from Day 1 | ❌ | YAGNI—start with ECS or plain Docker |
| gRPC everywhere | ❌ | Adds friction; use REST unless you really need tight contracts |
| 100% test coverage | 🤡 | Focus on contract tests + happy path E2E |
| Fancy service meshes | ❌ | Unless you're Netflix, maybe chill |
Migrating with an offshore team? Keep your tech decisions boring. Boring means understandable. Understandable means shippable - especially when you can’t tap someone on the shoulder at 4 p.m.
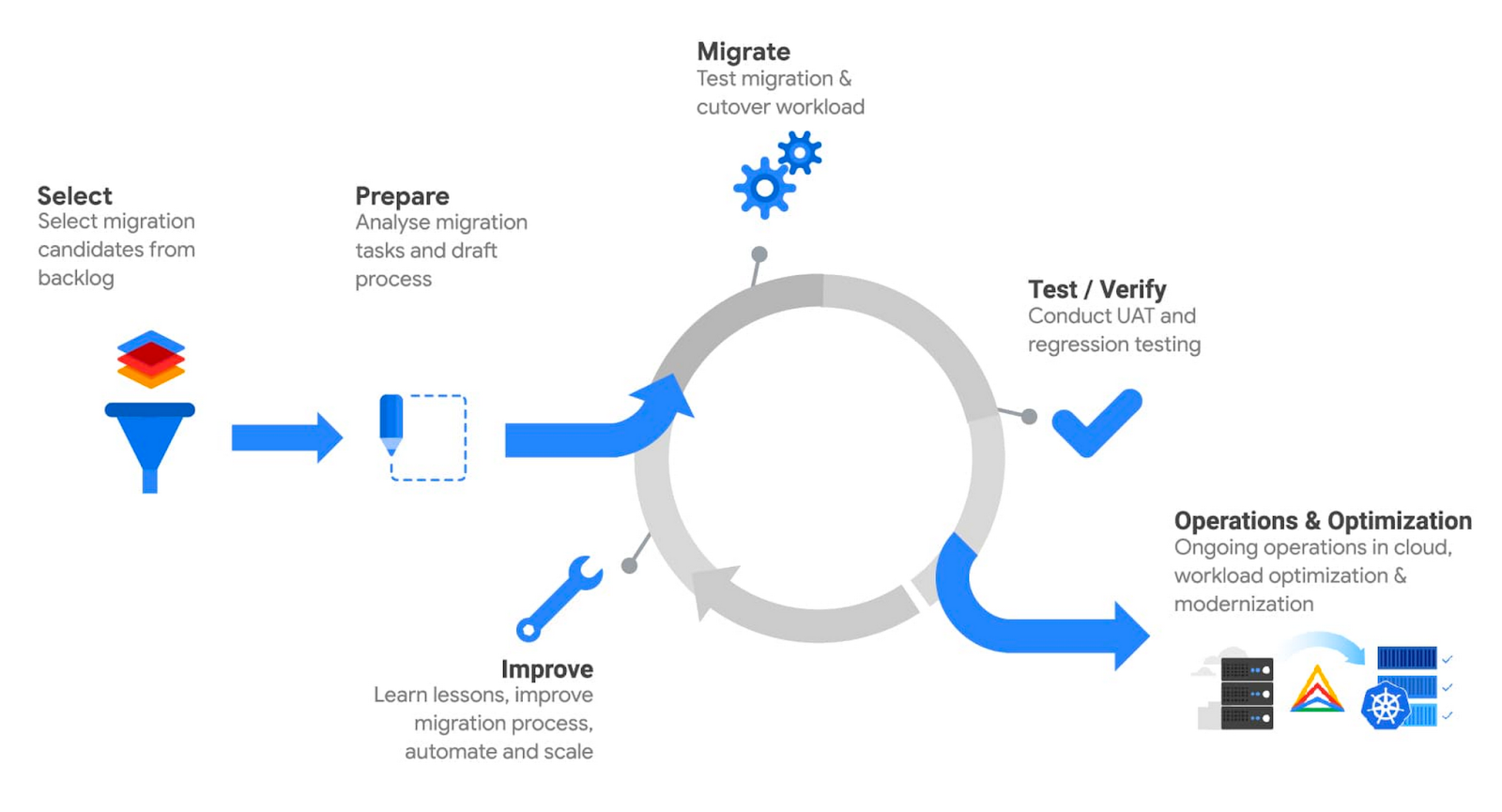
A Phased Migration Roadmap That Doesn’t Suck
Enough theory - here’s what a sane offshore migration might look like.
Phase 0: Set the Table
- Do a capability map of your monolith.
- Identify critical domains and pain points.
- Map these to proposed microservices.
- Decide: Greenfield rewrite vs. Strangler pattern?
- Get everyone aligned - including offshore leads.
Phase 1: Pilot a Thin Slice
- Pick one low-risk domain (e.g., Notifications).
- Create the microservice with its own CI/CD.
- Deploy alongside the monolith.
- Monitor and debug how the offshore team handles delivery, testing, and prod support.
Phase 2: Expand Horizontally
- Add 2–3 more services in parallel.
- Use consistent tooling and infra.
- Offshore teams get end-to-end ownership for their services.
Phase 3: Introduce API Gateway + Observability
- Centralize routing via API Gateway (we like Kong or AWS Gateway).
- Add tracing (OpenTelemetry or Honeycomb), logging (ELK or Loki), metrics (Prometheus/Grafana).
- Set up contract testing between services.
Phase 4: Data Decoupling + Monolith Retirements
- Begin strangler migrations for reads.
- Migrate writes one service at a time.
- Sunset parts of the monolith gradually.
Phase 5: Harden, Scale, Document
- Pen tests, chaos tests, failover drills.
- Infra-as-code maturity (Terraform, GitOps).
- Write real docs - not Notion pages that say “TBD.”
Is it slow? Yup. Is it worth it? Also yup.

What We Got Wrong (And Eventually Fixed)
No migration is perfect. Some of our faceplants:
- Under-communicated changes: We once renamed a shared Kafka topic without looping in the offshore team. They spent 3 days debugging why everything broke. Always share context. Async, in writing.
- Overcomplicated infra: Early on, we pushed every service to run on Kubernetes. Burnout and confusion ensued. Now we start with Docker Compose and move up only if needed.
- Poor QA coverage: We assumed "unit tests will catch issues." They didn’t. Now we bake in contract tests and run nightly E2E regression with prod-like data.
- Time-zone neglect: You can’t ship efficiently if the offshore team needs your input and you’re asleep. We now front-load spec writing and review sessions, so they’re unblocked during their hours.

Reality Check: Offshore Doesn’t Mean “Outsource It and Pray”
Offshore success during a microservices migration is less about geography and more about responsibility architecture.
Give teams real ownership, not just Jira tickets. Let them ship, monitor, and fix their services. Invest in onboarding, mentorship, and devex. We’ve seen junior offshore engineers outperform onshore seniors - when they’re trusted and equipped right.
And yes, budget extra for overlap hours, documentation debt, and the occasional “hey, we broke prod” incident.
You’ll sleep better.
Wrap-up
Migrating from a monolith to microservices is one of those high-risk, high-reward bets that can either level up your engineering org - or send it into existential crisis mode. But if you plan it like a product, empower your offshore team like owners, and avoid shiny-tool distractions, it’s absolutely doable.
One service at a time. One lesson at a time. One cold brew at a time.
Want a battle-tested crew to help you plan or execute your microservice migration? Ping us at 1985. We’ll bring the diagrams, the Terraform, and the therapy.
FAQ
1. What’s the biggest risk in moving from monolith to microservices with an offshore team?
The biggest risk isn’t tech - it’s misalignment. Distributed teams can fall into the trap of duplicating work, missing shared context, or implementing services that don’t mesh. The risk multiplies when domain boundaries are fuzzy or when ownership isn't clearly defined.
2. How do I decide between a full rewrite and a strangler pattern?
Use the strangler pattern if your monolith is mission-critical and can't afford downtime. It lets you peel off functionality incrementally. Go for a rewrite only if the existing codebase is truly unsalvageable and business pressure allows for a long freeze on feature work.
3. Should my offshore team own entire services or just contribute modules?
Entire services. Microservices work best when a team has full lifecycle ownership - build, test, deploy, monitor. This empowers offshore squads to move independently and reduces bottlenecks caused by fractured responsibility.
4. How do I handle communication gaps across time zones?
Asynchronous clarity beats real-time chaos. Document decisions religiously. Over-communicate specs and edge cases. Use video walkthroughs, architectural diagrams, and daily summaries. Reserve overlap hours for unblockers, not status updates.
5. What’s the right team structure for a distributed microservices migration?
Domain-aligned squads work best - each owning a business capability. Appoint a domain lead who ensures consistency and long-term vision. Cross-cutting concerns like CI/CD and observability can be owned by a shared platform team.
6. How should we handle shared data during migration?
Don’t. Shared data is a trap. Establish clear ownership per service. Use read replicas, change-data-capture pipelines, or anti-corruption layers to handle transitional reads. Avoid write conflicts by centralizing responsibility during migration phases.
7. How do we avoid overengineering from day one?
Resist the urge to Kubernetes-everything or enforce 12-factor orthodoxy too early. Start with Docker Compose, REST APIs, and shared tools. Validate service boundaries and workflows first, then optimize infrastructure once usage patterns stabilize.
8. How long does a typical microservices migration take when done offshore?
It depends on the size of the monolith and the number of domains, but a meaningful migration usually spans 9 to 18 months. Early wins are possible within 3 months if you isolate low-risk services, but full decoupling takes time and iteration.
9. What tools can improve visibility and confidence during the migration?
Invest early in observability. Use OpenTelemetry for tracing, Prometheus and Grafana for metrics, and centralized logging via ELK or Loki. Feature flag tools like LaunchDarkly or Flagsmith can help you test without fear.
10. How do we ensure offshore teams stay motivated and aligned during a long migration?
Give them real ownership, not just task tickets. Let them lead service design, present at internal demos, fix production issues, and own documentation. Recognition, autonomy, and a sense of product impact go a long way - even across oceans.


