QA on Autopilot: Setting Up CI/CD Pipelines for Offshore Projects
Toolchain tips, workflow hacks, and hard lessons from real offshore sprints.


Because “it works on my machine” isn’t a QA strategy
You’ve got devs in Bangalore, QA in Cebu, a PM somewhere between Munich and mild burnout, and a founder in Palo Alto who thinks “CI/CD” is just a fancy Git command. Welcome to the wonderful world of offshore product engineering - where deadlines cross time zones faster than context, and your test coverage better travel better than your code.
We’ve run dozens of distributed sprints. We’ve shipped fintech dashboards, Web3 wallets (RIP), B2B platforms with more feature flags than users. And we’ve faceplanted in production enough times to know: a half-baked CI/CD pipeline isn’t a process gap. It’s a trust tax.
So here’s the no-nonsense playbook: what works, what breaks, and how we keep QA humming even when half the team’s asleep.

The Time-Zone Tax Is Real (But Automations Don’t Sleep)
“It’ll be fixed tomorrow” is great… unless it breaks everything tonight.
We once had a dev push a "small fix" to a payment module at 6:45 p.m. IST. QA caught the regression - at 7 a.m. their time. Fix didn’t ship till two days later. Cue angry emails from an investor demo that crashed mid-payment.
Multiply that delay across modules and you’ve got yourself a slow bleed.
Here’s what we’ve learned: you can’t outrun time zones, but you can out-automate them.
So we added guardrails:
- Every pull request runs linting, tests, and static analysis. No review? No merge.
- Every merge to main triggers a staging build - complete with E2E and visual regression tests.
- Every production deploy includes smoke tests, API heartbeat checks, and alerting hooks.
It’s less “move fast and break things” and more “move smart so you don’t break at 3 a.m.”
If you’re serious about distributed QA, your pipeline should replace Slack pings with scripts. Humans can’t scale sleep. Bots don’t need it.
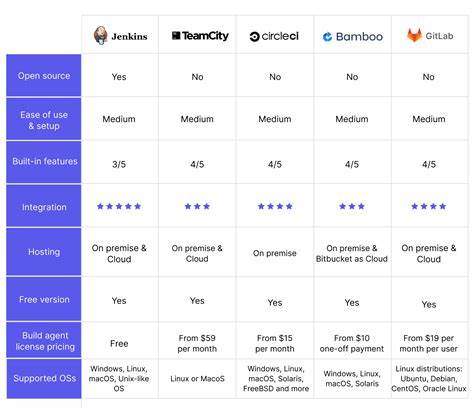
Toolchain Smackdown: What Actually Works
Because every DevOps forum sounds like a JetBrains vs. Vim street fight.
We’ve trialed more CI/CD combos than a college kid trying majors. Some stuck. Some cost us weekends.
Here’s what we’ve actually battle-tested and still like in 2025:
1. GitHub Actions
Great for fast-moving startups. Config-as-code, nice ecosystem, and matrix builds for multi-version testing. Secret handling is clean. And hey - it’s free for public repos.
2. GitLab CI/CD
Not as trendy, but solid. If you’re on GitLab anyway, the native CI is tight. It’s verbose (YAML-palooza) but reliable. Self-hosted runners are great for air-gapped infra.
3. CircleCI
Speed king. Their Docker layer caching is a lifesaver on complex builds. Expensive at scale, but worth it if your suite takes longer than your lunch break.
4. Playwright + Percy
Cypress is popular, but Playwright’s growing on us. Especially with Percy’s visual diffing. Layout bugs don’t always break tests - but they do break trust.
5. Sentry
Production’s tattletale. Tells you what blew up, when, and who wrote the code that did it. Pair it with release tracking and you get instant incident context.
Honorable mentions:
- Datadog RUM for frontend perf
- k6 for load testing
- TruffleHog for secret scanning (saved us once from shipping a real API key. Oof.)

Our Default Offshore CI/CD Template (Steal This)
We’ve deployed this to 17 teams. Break it at your own peril.
Step 1: On every PR
- ESLint + Prettier
- Jest or Mocha unit tests
- Codecov thresholds (>80%)
- GitGuardian secret scan
- PR title linter (seriously - clean titles save time)
Step 2: On merge to main
- Auto build + deploy to staging
- Cypress E2E runs
- Percy visual diff
- Slack bot pings #qa-review with pass/fail matrix
Step 3: Nightly jobs
- Full test sweep (unit, integration, API)
- Dependency scans (Snyk, npm audit)
- Backup integrity checks (we’ve seen backups fail silently - nightmare fuel)
- Faker.js seed verification (yes, fake data needs QA too)
Step 4: Prod deploy
- Canary first, then blue-green switch
- Post-deploy smoke tests (Postman/k6)
- Sentry release tracking + alert hook
- Rollback script pre-validated and green
This isn’t just process theater. This stack has saved us from deploying broken login flows, expired keys, and even one accidental dark mode apocalypse (don’t ask).

What We Got Wrong (And Fixed the Hard Way)
Our CI/CD hall of shame: presented without redaction.
We’ve made all the mistakes so you don’t have to. Actually, we still make some - just fewer and dumber.
❌ QA sign-off lag
We used to block deploys on manual QA sign-offs. Guess what? Half the bugs went live while waiting for approvals.
✅ Fix: Automate deploy gates. Make green tests the new thumbs-up.
❌ Environment drift
Dev envs passed. CI envs failed. Why? Different data fixtures, broken seed scripts. Classic offshore whoops.
✅ Fix: Commit fixture generators. Version your test data.
❌ Flaky E2E tests
Our test suite was the boy who cried bug. Half the failures were false alarms. Everyone started ignoring them.
✅ Fix: Isolate flaky tests, flag them, fix them. Or delete them - mercilessly.
❌ Over-reliance on E2E
We leaned too hard on E2E as the canary. It slowed us down, missed obvious logic bugs, and failed silently.
✅ Fix: Redistribute trust. Unit tests for logic. Integration for contracts. E2E for workflows. Pyramid, not plate.
Offshore Testing: Don’t Just Automate, Orchestrate
Your QA isn’t a test suite. It’s an ecosystem.
We stopped treating QA like a final gatekeeper. It’s now an orchestrated service with its own rhythms.
What worked:
- Smoke tests as code
No more spreadsheets. Our QA team codes their own smoke tests that run on every deploy. Debug logs included. - Geo-distributed test runners
CircleCI + Playwright running from Singapore, Frankfurt, and US-East. Real latency. Real edge cases. - Approval routing
Need a hotfix pushed at midnight? Local leads can greenlight if the build passes. No PM bottleneck required. - Ticket auto-gen
Failed test? Jenkins auto-files a Jira with logs, stack trace, screenshots, and replay link. No excuses. No ghost bugs. - Time-aware dashboards
We pipe Grafana alerts to QA’s timezone-adjusted dashboards. If a test failed at 4 a.m. their time, they see it at 9, not buried in yesterday’s chaos.

CI/CD Smells to Watch For
If you hear these phrases, hit pause. Something stinks.
“Let me check with QA.”
Translation: there’s no automation, just manual buffer time.
“It passed locally.”
Classic: local env doesn’t match CI. Probably missing a .env var or running MySQL 5.7.
“Tests only run before prod.”
You’re not doing CI/CD. You’re doing ‘hope and deploy.’
“Our test env isn’t HTTPS.”
Facepalm. Yes, this happened. The test passed because cert warnings were ignored.
Your Offshore CI/CD Scorecard
Grade yourself like you’re your own worst QA tester.
| Metric | Score (0–5) |
|---|---|
| PRs run tests pre-merge | |
| Auto deploy to staging | |
| Visual regression testing | |
| Test suite completes <10 mins | |
| Smoke tests on prod | |
| Failure reports include logs + screenshots | |
| Timezone-aware dashboards | |
| Infra-as-code tested too |
> Score: 30+? You’re flying.
< 20? Time for a pipeline intervention.
Tool Pairings That Actually Gel
Because tools don’t work alone. Like jazz bands, they need chemistry.
- GitHub + Cypress + Percy + Vercel
Great for fast frontends. Instant preview URLs. Designers love it. - GitLab + Playwright + AWS CDK
Infra-heavy teams, regulated sectors. Full-stack confidence. - Bitbucket + Bamboo + Selenium Grid
If you’re stuck with this, you’re probably stuck with Jira, too. Godspeed. - Jenkins + Bash + Groovy
Retro, powerful, and fragile. Like a 90s Nokia phone with a cracked screen that still works… until it doesn’t.
Wrap-up: QA on Autopilot Is About Trust, Not Tools
You don’t need a shinier CI tool. You need a system your team believes in.
One that:
- Prevents bugs from going live.
- Enables async handoffs across time zones.
- Documents failures without human babysitting.
When your pipeline has your back, your QA team gets to sleep. Your devs get instant feedback. And your product? It actually ships.
Want an offshore team that ships clean, fast, and fearlessly?
Talk to us at 1985. We’ve got the scars, scripts, and timezone hacks to prove it.
FAQ
1. What’s the biggest challenge with CI/CD in offshore setups?
The biggest challenge isn’t just tooling - it’s latency in feedback loops caused by time-zone differences. A failed test that goes unnoticed for 12 hours can delay releases and compound debugging. The solution isn’t to wake people up, it’s to build automated gates that catch and communicate issues asynchronously.
2. Should I prioritize unit tests, integration tests, or E2E in my CI/CD pipeline?
You need all three, but not equally. Unit tests should be your fastest and most plentiful - they catch issues at the source. Integration tests validate contracts between modules. E2E tests are important but fragile and slow, so they should focus on critical user flows. Follow the “test pyramid,” not the “test pancake.”
3. How do I ensure test data consistency across environments?
The key is to treat test data like code. Generate it programmatically using version-controlled seed scripts, and run those scripts during CI setup. Avoid manually curated staging DBs - they rot. Use snapshots or mocks when you can’t replicate real data easily, and always test the test data itself.
4. What’s the best way to get fast feedback without overloading my CI budget?
Use parallelism intelligently. Run lightweight tests (like linting and unit tests) on every PR, and batch heavier jobs (like full E2E) for merges or scheduled runs. Use Docker layer caching and smart job splitting in tools like CircleCI or GitHub Actions to cut runtime without burning dollars.
5. How do I prevent flaky tests from derailing offshore QA?
First, isolate them. Tag flaky tests so they don’t block pipelines but still log results. Use retry logic with limits to separate environmental failures from real ones. Once identified, fix them or quarantine them. Never normalize flakiness - it's CI’s version of technical debt.
6. What does “QA as code” actually mean in practice?
It means codifying smoke tests, sanity checks, and even environment validations into scripts that run automatically. Instead of relying on manual QA steps or spreadsheets, treat your QA logic as part of the codebase. This allows consistent, repeatable checks that can run at 3 a.m. without a human in sight.
7. How can I handle approvals across multiple time zones without blocking deploys?
Set up role-based approval proxies. For instance, allow regional leads or trusted senior engineers to approve changes within their domain. Pair this with alerts and dashboards that show deploy status in local time so that approval doesn’t depend on someone being awake halfway across the world.
8. What kind of visual regression testing is worth adding to offshore pipelines?
Tools like Percy or Chromatic plug into your test suite and capture UI snapshots on every build. If a visual change slips in - intentional or not - QA gets a diff view. It’s especially useful in offshore teams where verbal clarification of “this button shifted slightly” might take a day to resolve.
9. How do I monitor and debug test failures without someone watching the logs live?
Automate repro tickets. Your pipeline should capture test logs, stack traces, screenshots, and ideally a replay link. When something fails, it should auto-create a Jira (or similar) ticket with this payload. It saves hours and helps QA pick up where the CI left off, without asking “can you repro?”
10. Is CI/CD automation enough to replace manual QA for offshore projects?
No - but it dramatically reduces the manual surface area. Automation handles the routine and the regressions. Manual QA should focus on exploratory, UX, and non-deterministic edge cases. The goal is not to eliminate QA testers, but to free them from grunt work so they can test what machines can’t.


