The Discovery Framework That Kills Bad Ideas Faster
Stop burning cash on bad builds – see how our 4-Phase Discovery finds fatal flaws before coding starts.


How much capital did you really burn on your last "pivot"? Not just the dev hours, but the opportunity cost, the market window shrinking, the team morale cratering? Conventional wisdom blames execution, market timing, or funding. We see something different in the wreckage: most software ventures are fatally wounded before the first line of code is committed. They die quietly during inadequate discovery.
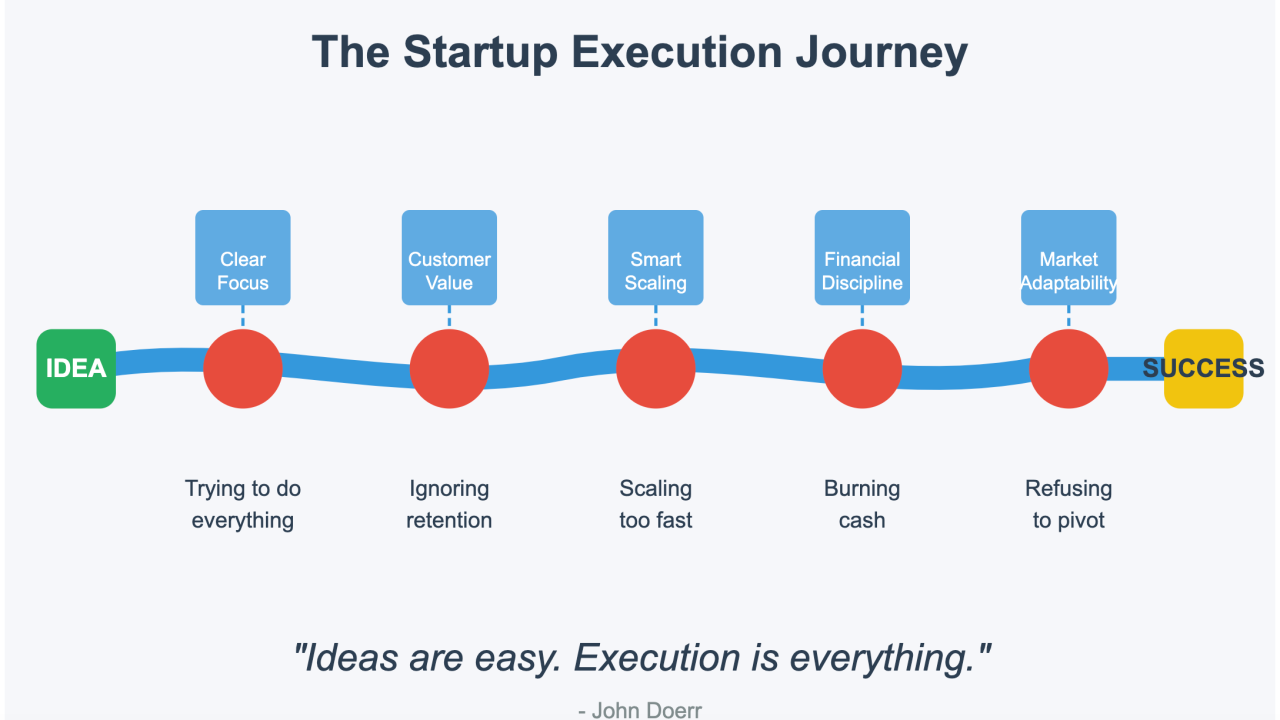
The standard "discovery phase" is often a flimsy checklist: gather requirements, pick a stack, estimate timelines. It’s a ritual, not a rigorous diagnostic. It’s why Gartner consistently finds that poor requirements definition is a leading cause of project failure – a problem costing businesses billions annually. It’s why your “agile” sprints feel like flailing, not iterating.
At 1985, we scrapped that playbook. We don’t do flimsy. We implement a 4-Phase Discovery Framework designed not just to plan the build, but to stress-test the entire venture – strategy, market, tech, and execution – before significant capital is deployed. This isn’t about avoiding failure; it’s about failing cheaply and early, often within the discovery itself, saving you millions and months down the line.
Think of it as the pre-mortem your investors wish you’d done.

Phase 1: Strategic Alignment & Risk Assessment – Beyond the Feature List
This is where most discovery processes falter, mistaking feature requests for strategy. We start elsewhere. We interrogate the why.
Defining 'Why': Business Objectives & Market Fit
We force uncomfortable questions. What specific business metric must this software move? Is it reducing churn by X%? Increasing LTV by Y? Driving Z qualified leads? If the answer is vague ("increase engagement"), the project is already adrift. We need quantifiable targets.
Then, market fit. Who exactly is the initial user? What specific, acute pain point does this solve better than existing alternatives (including inertia)? We push past aspirational TAM slides to the gritty reality of the first 100 users.
A study by CB Insights analyzing startup failures consistently lists "No Market Need" as a top reason, accounting for over 35% of failures. Discovery must validate this before building.
Actionable Takeaway: Mandate that every major feature proposed must trace back to a specific, measurable business objective and a validated user pain point solvable within their existing workflow. No objective? No feature.
Unearthing Assumptions: The Silent Killers
Every product idea rests on a stack of assumptions: "Users will tolerate manual data entry," "Our algorithm can achieve 95% accuracy," "Integration partners will provide timely API access." Most discovery glosses over these. We hunt them down.
We use techniques like Assumption Mapping to list every implicit and explicit belief underpinning the project's success. Then, we classify them by impact (high/low) and certainty (known/unknown). The high-impact, unknown assumptions become primary targets for de-risking in later phases.
Research suggests cognitive biases heavily influence early-stage product decisions. Confirmation bias leads teams to seek data supporting assumptions, ignoring contradictory evidence. A structured assumption audit counteracts this.
Actionable Takeaway: Create an "Assumption Register" during discovery. For each core assumption, define how and when it will be validated (e.g., user interviews, technical spikes, partner LOIs). Treat unvalidated high-impact assumptions as critical risks.
Mapping the Minefield: Proactive Risk Triage
Risk isn't just about timelines slipping. It's regulatory hurdles, key personnel dependencies, platform scalability limits, third-party API instability, security vulnerabilities. Standard discovery might list a few; we build a comprehensive Risk Matrix.
We categorize risks (Technical, Market, Operational, Financial, Legal/Compliance) and score them based on probability and impact. Crucially, we assign ownership and define mitigation strategies during discovery. This isn't a CYA exercise; it's building resilience into the plan from day one.
Internal data from 1985’s project audits across dozens of engagements shows that over 60% of significant budget overruns trace back to risks identifiable in Phase 1 but left unaddressed until development was underway.
Actionable Takeaway: Don't just list risks; assign a mitigation cost/effort estimate and bake it into the roadmap. If a risk's mitigation cost is prohibitive, question the project's viability now.
Phase 2: Deep Dive & Solution Blueprinting – Defining the 'What' and 'How'
With strategy validated and risks mapped, we move to the solution. But again, we avoid the trap of just listing features. We build a blueprint.
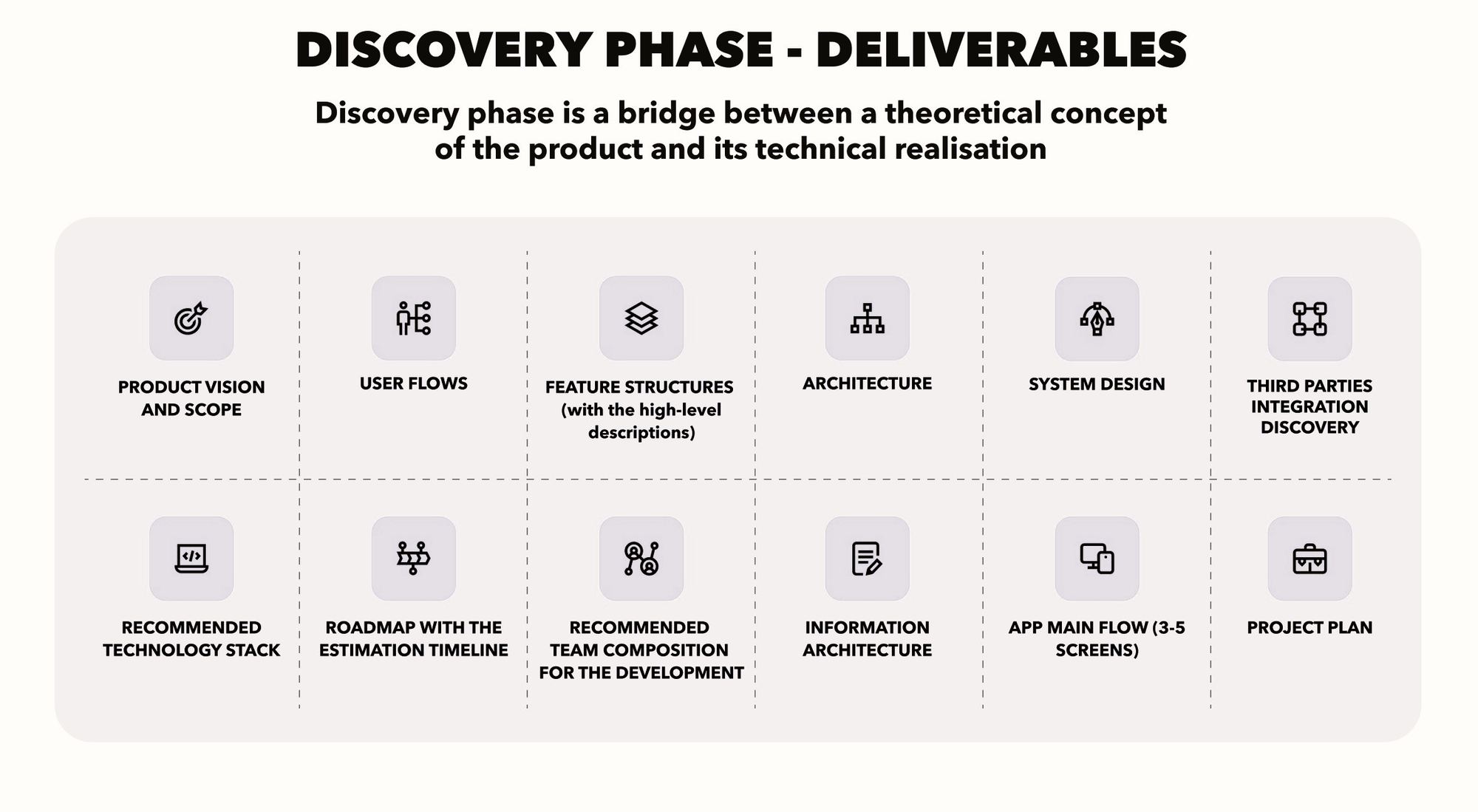
User Journeys, Not Just User Stories
User stories are tactical. User journeys are strategic. We map the end-to-end experience for key user personas, focusing on the flow and value exchange at each step. This reveals interaction gaps, points of friction, and opportunities for delight that a flat backlog misses.
This isn't about pixel-perfect wireframes yet. It's about understanding the logic of the user's interaction with the system to achieve their goal, informed by Phase 1's objectives.
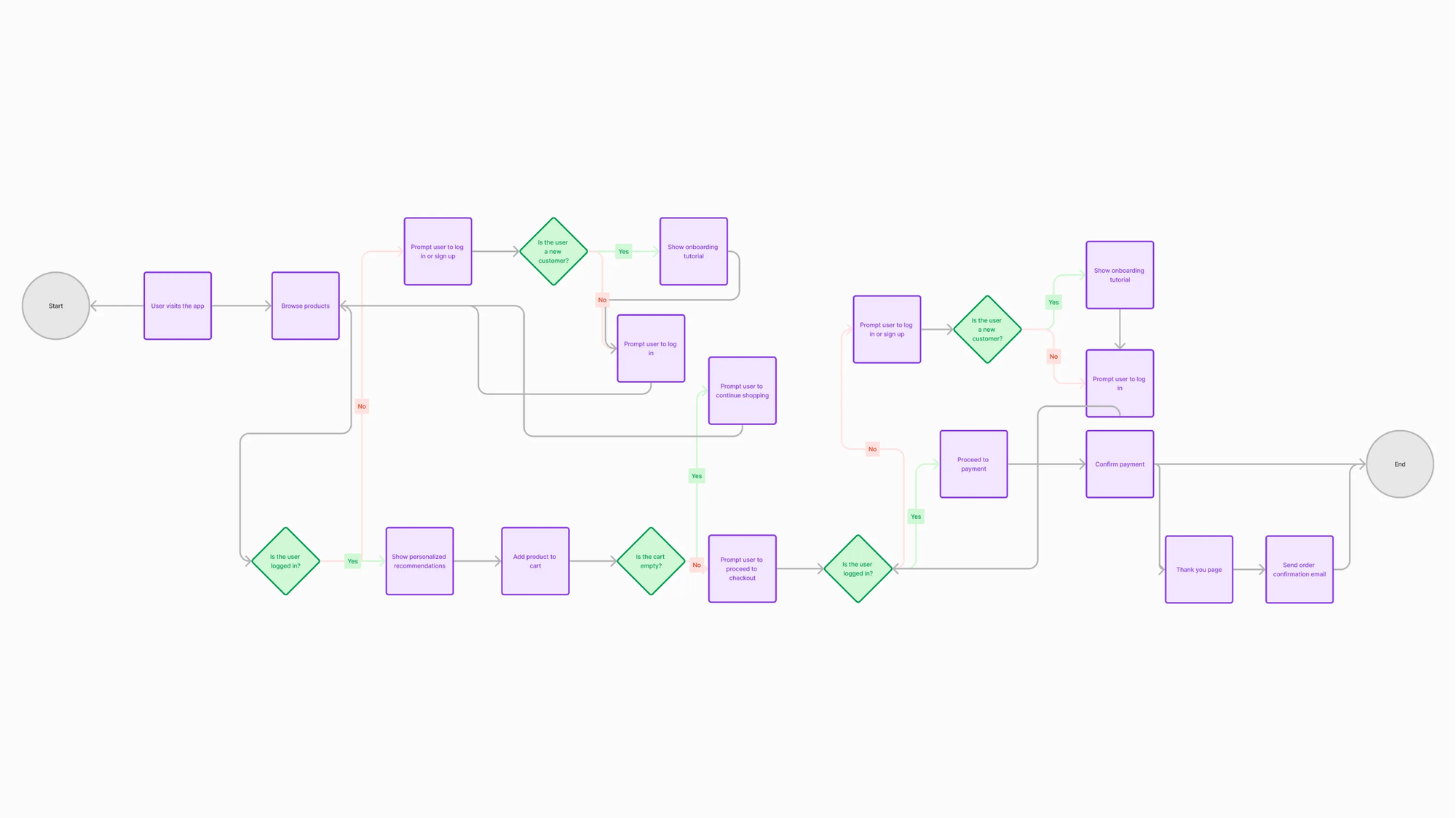
According to Forrester Research, a well-designed UX can yield conversion rates up to 400%. Journey mapping is foundational to that design.
Actionable Takeaway: Prioritize mapping the critical 2-3 user journeys first. Use simple flowcharts or tools like Miro. Get cross-functional input (product, dev, design, support) to identify blind spots.
Functionality Mapping: Core vs. Edge
The dreaded scope creep often starts here. Ideas multiply. "Wouldn't it be cool if..." We enforce ruthless prioritization based on the validated objectives and user journeys from Phase 1.
We categorize proposed functionality:
- Core: Essential for the primary user journey and delivering the core value proposition (MVP).
- Supporting: Enhances the core experience but not strictly essential for launch.
- Edge: Nice-to-haves, potential future features, or features serving secondary user segments.
This isn't just about labeling; it's about defining dependencies and understanding the minimum viable product that actually delivers strategic value.
The Standish Group's CHAOS reports have historically shown that a significant percentage of features developed are rarely or never used. While figures vary year to year, the principle holds: over-scoping wastes resources.
Actionable Takeaway: Use a simple matrix: Feature vs. Business Objective vs. Core User Journey. If a feature doesn't strongly support a primary objective and journey, it's not MVP. Be brutal.
Initial Architecture: Sketching the Skeleton
We don't finalize the tech stack yet, but we start sketching the system's architecture. How will major components interact? Where will data reside? What are the key integration points? What are the likely scalability bottlenecks based on projected usage?
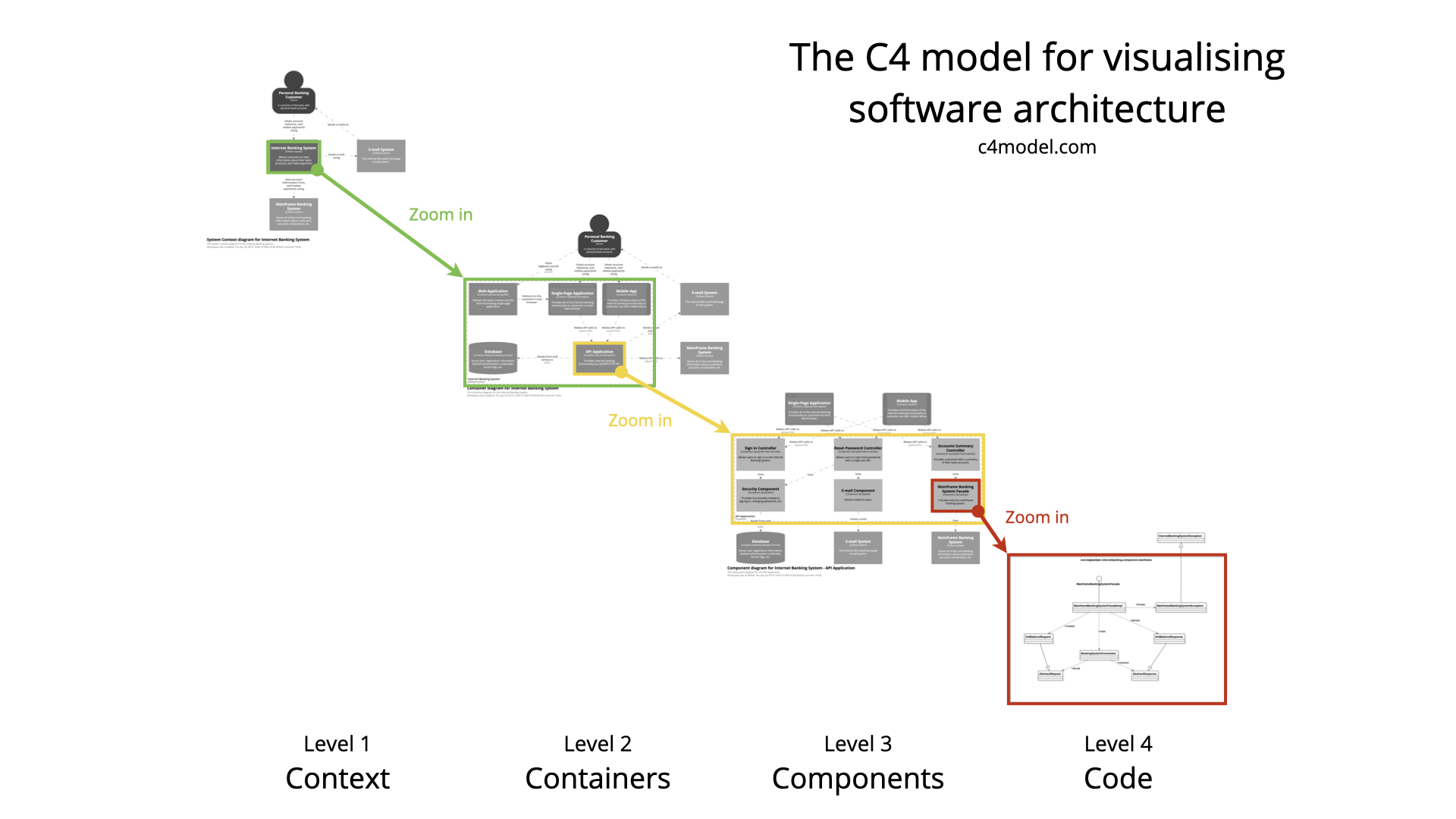
This isn't about choosing specific databases or frameworks yet. It's about understanding the shape of the system and identifying areas requiring technical validation in the next phase. We focus on modularity, potential failure points, and data flow.
Technical debt, often accrued through poor early architectural decisions, can consume up to 40% of development time, hindering feature velocity. Early architectural thinking mitigates this.
Actionable Takeaway: Create high-level diagrams (e.g., C4 model context/container diagrams). Identify the top 3-5 architectural risks or unknowns that need validation. Don't optimize prematurely, but anticipate major load points.
Vague Requirements vs. Blueprint-Driven Discovery
| Aspect | Vague "Requirements Gathering" Approach | 1985 Blueprint-Driven Approach (Phase 1 & 2) |
|---|---|---|
| Focus | Feature list | Business objectives, user journeys, risks |
| Output | Document/backlog of requests | Validated strategy, risk register, core journeys, architectural sketch |
| Risk Handling | Reactive (addressed during dev) | Proactive (identified, assessed, mitigation planned) |
| Scope Control | Poor; prone to creep | High; based on core objectives/journeys |
| Estimation | Highly inaccurate | More grounded, based on defined scope & risks |
| Tech Decisions | Often based on preference/familiarity | Based on requirements, risks, planned validation |
| Failure Mode | Build the wrong thing / run out of budget | Fail fast/cheap during discovery, pivot informedly |
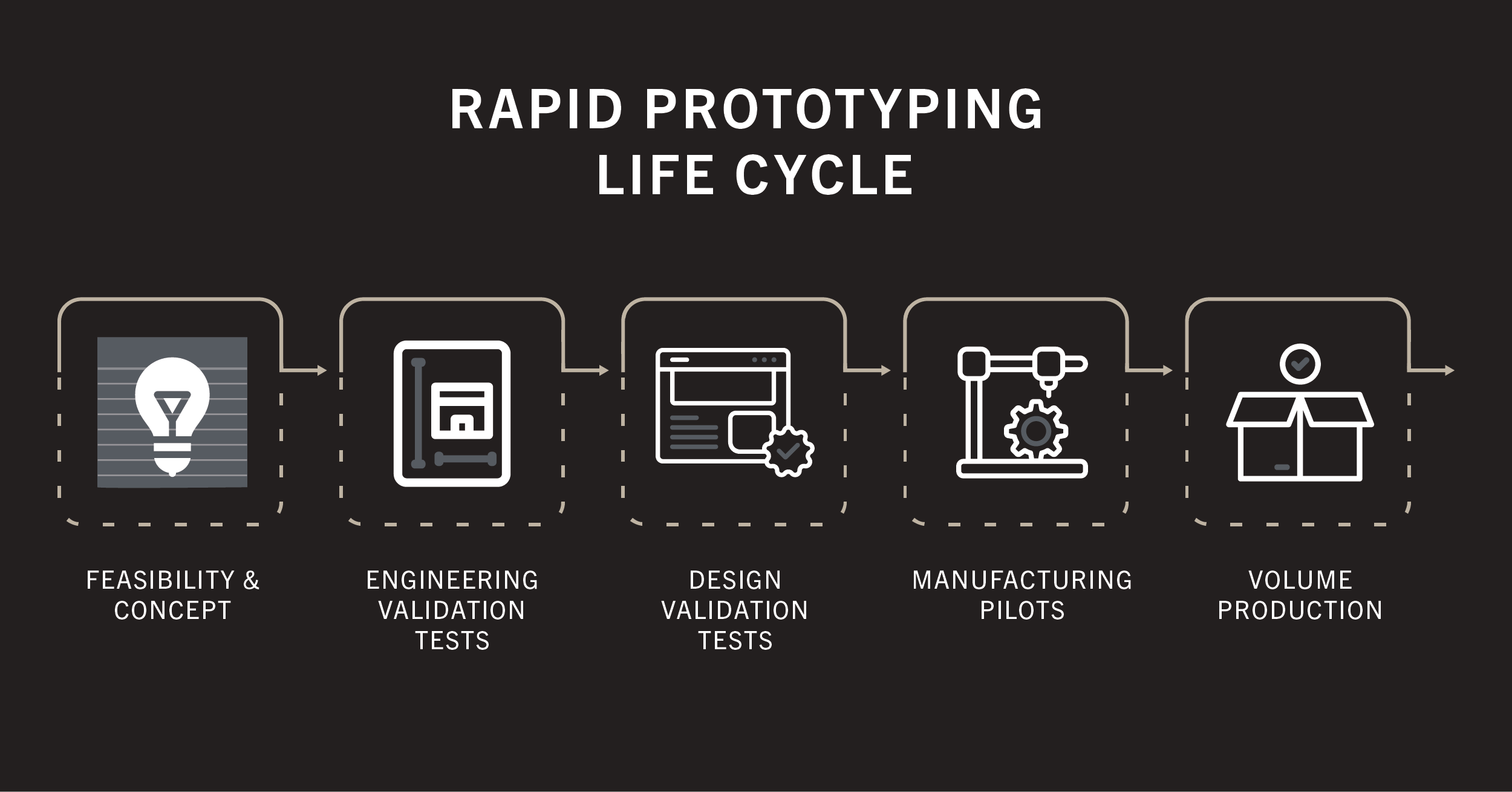
Phase 3: Technical Validation & Prototyping – Reality Check
Ideas are cheap. Execution is everything. Phase 3 is where we pressure-test the riskiest technical assumptions identified in Phases 1 and 2. Can this actually be built efficiently, scalably, and reliably?
Spike Tasks: Targeted Experiments
Forget lengthy R&D cycles. We use focused "spikes" – short, time-boxed investigations (typically 1-3 days) – to answer specific technical questions. Can library X handle our expected data volume? How complex is integrating with API Y? What's the performance overhead of approach Z?
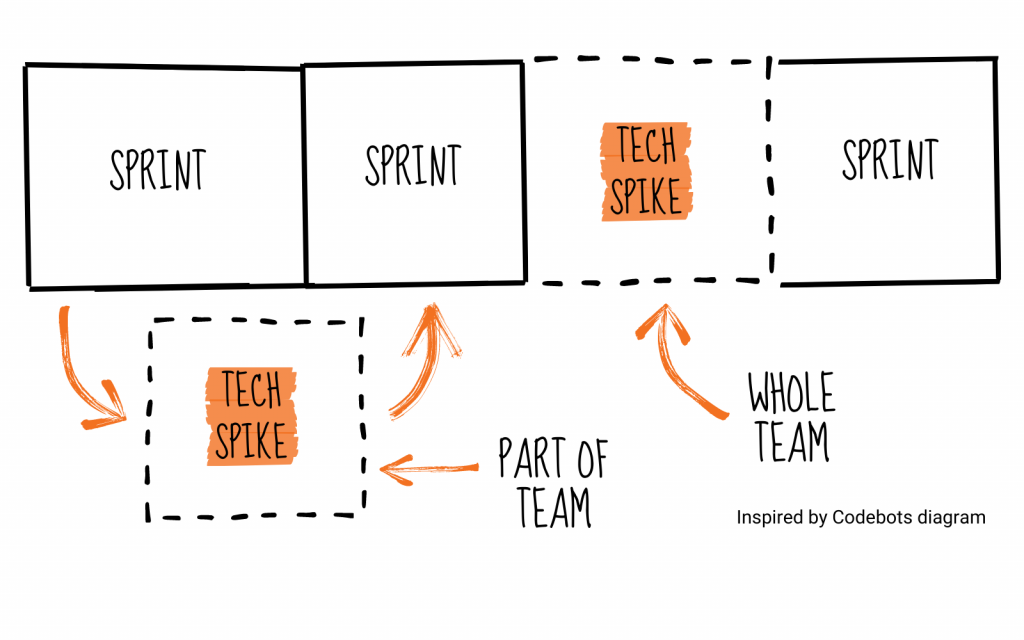
Spikes deliver concrete answers, code snippets, or performance benchmarks, replacing guesswork with data.
Studies on software estimation accuracy show that uncertainty is highest in early stages. Technical spikes directly reduce this uncertainty for key components.
Actionable Takeaway: Budget explicitly for spike tasks during discovery (e.g., 5-10% of discovery effort). Prioritize spikes based on the highest technical risks identified in Phase 2. Time-box them ruthlessly.
Proof-of-Concept (PoC): Killing Bad Ideas Cheaply
For major architectural risks or novel interactions, a spike isn't enough. We build targeted PoCs. This isn't a polished prototype; it's often ugly, backend-focused code designed to prove or disprove a core technical hypothesis. Can the core algorithm scale? Can the critical third-party systems really integrate smoothly?
A successful PoC builds confidence. A failed PoC is even more valuable – it prevents you from building on flawed foundations.

The cost of fixing a defect found post-release is exponentially higher (often cited as 100x or more) than fixing it during the design/discovery phase. PoCs are cheap defect prevention.
Actionable Takeaway: Define clear success/failure criteria for each PoC before starting. Focus the PoC only on the core risk being tested; avoid adding unrelated features.
Stack Selection: Evidence Over Hype
Only now, armed with insights from Phases 1-3, do we make informed decisions about the core technology stack. The choice isn't driven by developer preference or the latest trends on Hacker News. It's driven by:
- Alignment with validated functional and non-functional requirements (scalability, security, performance).
- Results from technical spikes and PoCs.
- Team expertise and ecosystem maturity.
- Long-term maintenance considerations.
"As one of our MedTech CTO clients put it: 'Outsourcing failed repeatedly until our partner forced us through a discovery that validated tech choices against our specific compliance and data velocity needs, not just their preferred stack. 1985 did that.'"
While hard data is scarce, anecdotal evidence and industry analysis suggest significant costs associated with choosing inappropriate technology stacks, leading to recruitment difficulties, slow development, and scaling challenges. (Trend observed in 1985 client post-mortems before engagement).
Actionable Takeaway: Create a decision matrix for key technology choices (e.g., backend framework, database, cloud provider). Score options against criteria derived from Phases 1-3 (performance needs, team skills, risk profile, ecosystem). Justify the final choice with data.
Phase 4: Roadmap & Delivery Cadence – The Launchpad
The final phase translates the validated blueprint and technical decisions into an actionable execution plan. This isn't just a Gantt chart; it's about setting the rhythm for successful delivery.

Prioritization That Sticks: MVP & Beyond
Using the Core/Supporting/Edge mapping from Phase 2, we define a realistic MVP scope. What's the absolute minimum needed to test the core hypothesis with real users and deliver initial value? We then sequence subsequent releases (Phase 2, Phase 3 features) based on validated learning and strategic priorities.

This roadmap isn't set in stone, but it provides a clear trajectory and prevents the "everything is urgent" chaos.
Agile methodologies emphasize delivering working software frequently. A well-defined MVP and phased roadmap enable this, providing faster feedback loops.
Actionable Takeaway: Define MVP exit criteria: What specific user behavior or data point will validate the core hypothesis? Plan for learning and adaptation after the MVP launch.
Team Composition & Communication Flow
Who builds this? What skills are needed? How will the client team and the 1985 team collaborate? We define roles, responsibilities, and communication cadences (standups, demos, retrospectives, stakeholder updates).
Crucially, we establish clear channels for decision-making and escalation. Ambiguity here breeds delays and frustration.
Poor communication is consistently cited as a major factor in project failure .
Actionable Takeaway: Create a simple Communication Plan: Who meets when? What's the agenda? What tool is used? Who makes the final call on scope/priority disputes?
Estimation Without Illusion
With a defined MVP scope, validated technical approaches, and team structure, we can finally provide meaningful estimates. We typically use techniques like story points and velocity forecasting based on team composition and complexity analysis from earlier phases.
We provide a range, acknowledging inherent uncertainty, but it's grounded in the rigorous work done so far, not wet-finger-in-the-air guesses. We also factor in the mitigation efforts for risks identified in Phase 1.
Research indicates that estimation accuracy improves significantly when based on smaller, well-defined work items and historical data (or analogous data from discovery spikes/PoCs).
Actionable Takeaway: Break down the MVP into small, estimable chunks (e.g., user stories). Use relative sizing (story points) and estimate velocity based on team capacity and complexity. Include explicit contingency buffers tied to specific risks.
Defining 'Done': Avoiding Zombie Sprints
What does "Done" actually mean? Code complete? Tested? Deployed? Documented? Monitored? We establish a clear, shared Definition of Done (DoD) that typically includes automated tests passing, code review completed, QA sign-off, deployment to a staging environment, and basic monitoring hooks in place.
This prevents "Zombie Sprints" – iterations where features are "code complete" but not actually shippable or stable, accumulating hidden integration debt.
Continuous Integration/Continuous Deployment (CI/CD) practices, which rely on a strong DoD, are shown to improve deployment frequency, reduce lead times, and lower change failure rates.
Actionable Takeaway: Document your Definition of Done. Ensure it covers quality gates (testing, reviews) and deployability. Make it visible to the entire team and stakeholders. Hold yourselves accountable to it every sprint.

Stop Building on Sand
The allure of jumping straight into code is strong. It feels like progress. But building without rigorous discovery is like constructing a skyscraper on untested foundations. The cracks might not show immediately, but structural failure is inevitable.
Our 4-Phase Discovery Framework isn't an optional prelude; it's the most critical phase of software development. It’s where you kill bad ideas before they consume your budget, align technology with real business needs, and build a foundation for predictable, successful delivery. It transforms discovery from a box-ticking exercise into your most potent strategic weapon.
If your current development partner jumps straight to user stories without deeply interrogating your business objectives, mapping your assumptions, stress-testing technical risks, and defining a rigorous delivery cadence – you're likely already burning capital unnecessarily.
Does your discovery process actively try to break your assumptions? Does it quantify risk? Does it result in a blueprint, not just a backlog?
If your discovery doesn't cover the 5 critical risk areas (Strategic, Market, Technical, Operational, Financial) with clear mitigation plans before sprint zero, ping 1985. Let's build on rock, not sand.


