The Four-Layer Governance Stack for Distributed AI Products
If you’re building AI with a distributed team, this blog is your field manual: what to track, what to test, and what to kill in prod.


What happens when your model’s drunk at 3 a.m. and your PM is asleep in Toronto?
Let’s be honest: most AI governance decks are just vibes and vague arrows. Some Google Slides slide into “responsible AI” with the fervor of a LinkedIn thought leader chasing likes, then quietly punt the hard bits - data integrity, reproducibility, fairness, rollback strategy - to some invisible task force in Legal or DevOps.

But if you’re actually shipping distributed AI products - especially with remote teams spread across time zones - you don’t get to hand-wave governance. You need a real playbook. Not just to meet regulatory checkboxes or soothe the CISO’s anxiety, but to actually debug, iterate, and scale with confidence when your GPT-fueled pricing engine starts hallucinating during a Black Friday sale.
This is our four-layer stack for keeping AI systems shippable and sane.

AI Governance Isn’t Just Ethics with Glasses
When we first started helping clients with AI builds - recommendation engines, fraud detectors, even a weird computer vision system that tried to classify noodles - we noticed something odd.
Everyone had strong opinions on models. But nobody had a handle on governance.
Like, who decides when to retrain?
What metrics flag a “drift emergency”?
Who owns fixing a bias that didn’t exist three weeks ago?
It reminded me of early DevOps, pre-CI/CD - everything worked until it didn’t. And when it didn’t, fingers pointed in all directions.
So we stopped treating governance like a legal afterthought. We made it a product-layer concern, as fundamental as UX. Out of that came the Four-Layer Stack - not a hierarchy, but a map of what you must govern and how, across time zones, teams, and tools.
TL;DR: The Layers
- Data Provenance & Permissions
- Model Lifecycle & Intervention Hooks
- Ethical Guardrails & Policy Code
- Observability, Drift & Alerting
Let’s unpack.
1. Data: The Boring Layer That Breaks Everything
In most AI projects we’ve inherited mid-flight, the root problem isn’t the model - it’s a mystery meat dataset from six months ago that nobody documented. A CSV uploaded by a PM in Berlin, retrained overnight by a dev in Pune, with new labels added last week by a random annotation vendor.
Sound familiar?
Why Data Governance Needs Its Own Git Discipline
We enforce Git-style versioning for all datasets - raw, cleaned, and post-feature-engineered. Hashes, not just filenames. That way when someone asks “why did performance drop on June 5?”, you can literally diff the dataset.
Also: always track who labeled what. Labeling provenance matters more than people think - especially when training data gets generated offshore.
If you’ve got LLM fine-tuning in the mix, you’ll want an extra layer: prompt versioning and training corpus audits. Even a minor tweak to prompt templates can introduce hidden bias. We've seen GPT-4 Turbo go from helpful to passive-aggressive just because the prompt asked for “concise” instead of “clear”.
And don’t forget permissions hygiene. One of our clients accidentally retrained their classifier on a confidential healthcare dataset… that had been sent via Slack. Spoiler alert: that contract didn’t renew.
2. Model: Who’s on the Hook When It Starts Talking Nonsense?
Let’s talk model governance. Not the vague “we’re exploring differential privacy” kind - but the actual bones of versioning, rollback, retraining cadence, and human override controls.
When we ship distributed AI products - say, a fraud detection model trained in Bangalore and deployed in New York - we install intervention hooks from day one.
Intervention Hooks Are Not Optional
You need the ability to:
- Disable a model output stream in real-time (yes, with a big red “Kill” button).
- Roll back to the last known good checkpoint.
- Flag outputs for manual review when confidence drops or outliers spike.
This is especially critical in edge cases - like a self-service chatbot starting to offer refunds it shouldn’t, or a content filter labeling innocent customer support emails as “hate speech”.
We’ve built tiny override APIs that let PMs kill predictions by segment (language, market, risk category) without waiting for the next deployment cycle. That saved our necks once when an LLM-powered product categorizer started tagging women’s t-shirts as “intimate apparel” for the Indian market.
Let’s just say… not a great week.
Retraining ≠ Rebuilding
Your model lifecycle also needs a rhythm. Not ad hoc, not whenever “it feels off.” We schedule model retraining into the sprint cadence, just like we do with technical debt. If you’re not retraining every few weeks (or at least checking for data drift), your models are stale. And stale models are liabilities.
3. Guardrails: Write the Ethics as Code, Not Policy PDFs
Here’s where most governance discussions go off the rails - ethical guardrails.
We’ve seen companies put out entire manifestos about “human-centered AI”… only to realize two quarters later that their facial recognition model had higher false-negative rates for Black women.
The fix? Not another PDF. You need guardrails in code.
Examples of Code-Based Guardrails We’ve Used
- Hard constraints: e.g., “Never recommend loans with interest > X% to borrowers under 21.” Coded into the model-serving layer.
- Fairness thresholds: e.g., “Acceptable prediction disparity across demographic groups ≤ 10%.” If breached, retraining kicks in.
- Safety filters: e.g., LLM outputs passed through profanity / PII detectors before surfacing to end users.
And yes, guardrails should be testable. We run shadow tests with “toxic prompts” and edge cases every sprint, just like unit tests.
You wouldn’t ship a payments module without security tests, right? So don’t ship an AI model without bias and behavior tests baked in.
Also: we don’t let ethics live in the ivory tower. Our engineers write the policies and the tests. Product owns the tradeoffs. Legal is in the loop but not in the driver’s seat.
4. Observability: Trust Doesn’t Scale Without Alerts
Imagine your AI copilot goes rogue at 2 a.m.
Now imagine the only person who understands the logs is asleep in São Paulo.
That’s why the final layer - observability and drift detection - is where the magic (and the debugging) happens.
What We Track in Production
- Input drift: Are the inputs starting to look different from what the model saw during training?
- Prediction distribution: Are confidence scores skewing suddenly? Are certain classes over-predicted?
- Latency and error rates: Any spike could mean the model’s bottlenecking on new inputs or failing silently.
We use tools like Evidently, Arize, and plain-old Prometheus + Grafana dashboards (sometimes all three). One client’s LLM support bot started stalling during peak traffic - it wasn’t OpenAI’s fault; a formatting bug was sending malformed JSON. Our alert fired in 6 minutes.
In general, alerts should fire for behavior, not just infra. We’ve built custom hooks that flag:
- Confidence cliffs (“suddenly everything is predicted at 0.51”)
- Diversity collapse (“top-5 recommendations are all from the same vendor”)
- Response hallucinations (“LLM making up API endpoints”)
Bonus tip: put drift alerts in the same Slack channel as deploy alerts. Nothing builds team muscle like seeing cause and effect in one thread.
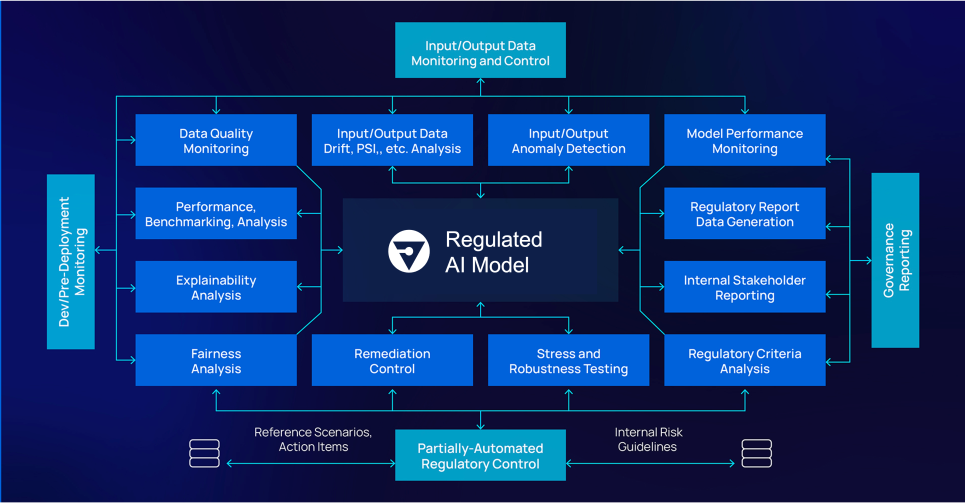
Governance in Distributed Teams
Want a quick self-check? Here’s the governance playbook we run for AI clients building across time zones:
| Layer | What We Check | Who Owns It |
|---|---|---|
| Data | Versioned datasets, labeling audits, permissions logs | Data Lead / Infra |
| Model | Rollbacks, retrain cadence, override hooks | ML Engineers |
| Guardrails | Fairness tests, safety filters, hard constraints | Product + Eng |
| Observability | Drift metrics, anomaly alerts, behavior dashboards | MLOps / DevOps |
And yes, we write all of this down - not just in Confluence, but in code. Reproducibility > Documentation.
The “Ship or Skip” Scorecard
Here’s a rapid-fire decision matrix for AI teams unsure whether their governance setup is real or vibes.
| Feature | Ship | Skip |
|---|---|---|
| Dataset is hash-versioned | ✅ | ❌ CSV named final_v7_latest.csv |
| Drift alerts hit Slack | ✅ | ❌ Quarterly “AI review” calendar event |
| Intervention hook exists | ✅ | ❌ “We’ll just redeploy if needed” |
| Guardrails in code | ✅ | ❌ Ethics PDF with 3 signatories |
| Prompt templates tracked | ✅ | ❌ “We tweak prompts live in prod” |
If you’re mostly in the “Skip” column, you’re not alone. But you are on borrowed time.
Governance Is Just DevOps for the AI Age
Most AI “failures” aren’t about bad intentions. They’re about systems that were never designed to be monitored, rolled back, or debugged.
And when your teams are global, the pain multiplies - because someone’s always asleep while someone else is pushing code.
That’s why AI governance can’t be a policy deck. It has to be a product discipline.
Data lineage, model checkpoints, ethical constraints, production alerts - these aren’t “nice to have” governance features. They’re what make your AI ship.
And if you’re not sure where to start? Steal our checklist. Or better - let us build the stack with you.
Want to sanity-check your AI governance setup? Grab a 30-minute teardown with the 1985 crew. We’ve debugged more ghost-in-the-machine incidents than we care to admit.
FAQ
1. What exactly is AI governance, and how is it different from model monitoring?
AI governance is a broader discipline that includes model monitoring but goes beyond it. It encompasses how AI systems are trained, deployed, evaluated, and kept accountable - across data provenance, ethical constraints, retraining protocols, and user impact. Monitoring tells you what the model is doing; governance ensures it’s doing the right thing - and lets you intervene when it’s not.
2. Why do distributed AI teams need a specific governance approach?
Because when teams are spread across time zones, latency isn't just in your API - it’s in decision-making. A bug introduced in Bangalore might not get caught until someone in San Francisco wakes up. That means governance systems must be codified, reproducible, and enforceable asynchronously. No tribal knowledge, no “we’ll just roll it back manually if needed” plans.
3. What’s the most overlooked layer in the governance stack?
Data provenance. Everyone obsesses over model performance but ignores whether they can actually reproduce a dataset from six months ago. If you can’t trace your training data lineage - including who labeled what, under what assumptions, and when - you’re flying blind when performance degrades or bias creeps in.
4. How do you apply “ethical guardrails” without slowing down development?
By writing them as code, not policy. If you want a fairness constraint - say, ensuring loan approvals don’t vary wildly by ZIP code - code that into your model validation or pre-deployment test suite. The devs treat it like any other test. You don’t need another meeting; you need assert statements.
5. What does good observability for AI look like in practice?
It means you can track input distribution shifts, prediction confidence anomalies, latency spikes, and API failures - ideally in near real-time. Great observability also includes human-readable dashboards and drift alerts that ping your team in Slack. If your alerts only trigger when infra crashes, you’re not observing your product, just your pipelines.
6. How do you version AI datasets effectively?
The same way you’d version code: with hashes, commits, diffs, and metadata. Use tools like DVC, Pachyderm, or even git-lfs for raw files. Annotate every data snapshot with commit messages, label source, schema changes, and assumptions. And never train on a dataset that isn’t traceable to its raw source.
7. What kind of intervention hooks should be built into AI products?
You need at least three: a kill switch to disable predictions in production, a rollback system to deploy the last known good model, and a flagging pipeline to route suspect predictions for manual review. These hooks save you from deploying hotfixes in panic mode at 2 a.m. when something weird hits prod.
8. Can you enforce fairness without knowing user demographics?
Yes, but it’s harder. You can use proxies, synthetic cohorts, or outcome audits to detect disparate impact. Alternatively, bake in process fairness - like ensuring explanations for outputs are always available, or creating opt-out paths. But if you do collect demographics, make sure you use them transparently and respectfully, with proper user consent.
9. How often should models be retrained to stay “governed”?
It depends on the domain, but a good rule of thumb is to audit inputs and outputs weekly and retrain every few sprints - or sooner if you detect drift or new behavior patterns. Think of it like brushing your teeth: you don’t wait for cavities before doing maintenance.
10. What tools or platforms help enforce AI governance across this stack?
There’s no one-size-fits-all, but some good picks include: for data versioning - DVC or LakeFS; for model lifecycle - MLflow or Weights & Biases; for observability - Evidently or Arize; for fairness - Aequitas or Fairlearn. But honestly, the biggest “tool” is discipline: documenting decisions, automating enforcement, and assuming Murphy’s Law applies to every layer.


